1. searborn doc & 강의 자료
User guide and tutorial — seaborn 0.13.2 documentation
seaborn.pydata.org
https://colab.research.google.com/drive/1QhYrFMfbqG2aJpikkjrizBVA0qKUGYdB#scrollTo=BglwIFM3qx7i
Google Colab Notebook
Run, share, and edit Python notebooks
colab.research.google.com
2. 데이터 형태별 맞는 그래프

https://seaborn.pydata.org/tutorial/function_overview.html#figure-level-vs-axes-level-functions
Overview of seaborn plotting functions — seaborn 0.13.2 documentation
Overview of seaborn plotting functions Most of your interactions with seaborn will happen through a set of plotting functions. Later chapters in the tutorial will explore the specific features offered by each function. This chapter will introduce, at a hig
seaborn.pydata.org
2. EDA
https://colab.research.google.com/drive/1kYGHyjpR70cHl6cGqw7f8X4qdiu3w8Vl#scrollTo=lwT1-j-eqWT_
Google Colab Notebook
Run, share, and edit Python notebooks
colab.research.google.com
데이터 유형
- 수치형 데이터 (연속형,이산형) : 사칙연산 가능
- 범주형 데이터 중 순서형 데이터: 사칙 연산 불가. (학점 4.0 으로 사칙연산 안됨)
- 명목형 데이터 (개 품종, 성별 등)
상관관계
- 상관관계 r=0이면 학습에 쓰지 않는다. 절댓값 1에 가까울 수록 쓰기 좋다.
왜도
- 정규분포가 어디로 치우쳤냐
- median 중위값, mode 최빈값, mean 평균
- mean은 이상치 때문에 중위값에서 이상치 쪽으로 멀어진다.
첨도
- 정규분포가 얼마나 뾰족하냐
타이타닉 EDA
https://colab.research.google.com/drive/1uPpcTw7OVgWY5uZvgC0vZcAT76XbTRYn#scrollTo=4_ghx0rP452l
Google Colab Notebook
Run, share, and edit Python notebooks
colab.research.google.com
- 수치형,범주형 데이터 구분
> 수치형 데이터 중 통계 냈을 때 깔끔하게 떨어지면 범주형 데이터(순서형 데이터)일 확률이 큼
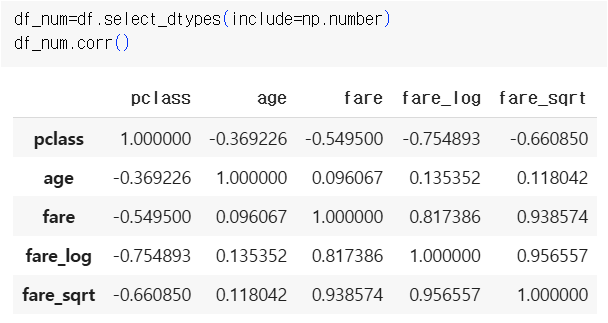
df.select_dtypes(include=np.number)
df.select_dtypes(exclude=np.number)- 중복 데이터 drop, 순서형 데이터 'str'로 바꾸기
통계분석
첨도/왜도/이상치
- 통계분석(describe)/첨도(kurt)/왜도(skew)/이상치 분석
- skew (0 완전대칭/ 양수 오른쪽 꼬리 김/ 음수 왼쪽 꼬리 김)
- kurt ( 3 정규분포 유사 / 3 이상 뾰족함 / 3 이하 평평 )


상관관계
- 절대값이 1에 가까울 수록 상관관계 있음, 0에 가까우면 없음

교차분석
- crosstab method
# crosstab
pd.crosstab(df['sex'],df['survived'],
margins=True,# margins: 합계 표시
# normalize='all', # 정규분포
normalize='index' # 인덱스 기준
)
결측치 > 치환
https://colab.research.google.com/drive/1ditj7-TKa6C-6A_PRhWRgm7PK1C3bosH
Google Colab Notebook
Run, share, and edit Python notebooks
colab.research.google.com
- df.isnull()로 조회 -> df.dropna()로 제거
- df.fillna()로 채우기
- sklearn imputer로 채우기
내 블로그 보는 사람들은 이런 사족이 더 재밌겠지... ㅋㅋ
일단 통계 분석은 좀 해봤었는데, 왜도 첨도는 이미 알고 있었고, 시각화도 좀 해봤었다.
상관관계(corr), 교차분석(crosstab)은 안해봐서 흥미로웠고, 결측치는 fillna 정도까지 해봤지 imputer은 생각도 안해봤었다. 음 여러모로 좀 배운 바가 있는 것 같다. 무엇보다 이젠 코랩에다 주석으로 어떤 그래프를 어떤 방식으로 그리고 싶다고 적어주면 알아서 싹다 해준다는거...너무 놀랍다. 이젠 정말 아이디어가 중요해진 시대인 것 같다. 나중에는 인공지능 개발자가 이런 것 마저도 다 해줄 수 있다고 하는데... 마법사가 주문 한번 외우는 걸로 온갖 마법을 부리는 것처럼 이젠 말 한마디로 알아서 모든 프로그램이 만들어지는 세상이 오지 않을까 한다. 중요해진 건 창의성일 것 같다...!
이번주 금요일에 타이타닉 데이터셋 경진 대회 한다는데, 솔직히 잘할 수 있을 지는 의문이다. 이거 어떻게 공부해야할 지 조금 막막해서 전에 알려주신 공부 방법 다시 볼 생각이다.
'개발공부 > SK Networks Family AI bootcamp 강의노트' 카테고리의 다른 글
| 17일차 [ numpy 심화 ] (0) | 2025.02.06 |
|---|---|
| 17일차 [Bike sharing demand 데이터 분석/ 머신러닝 개요 / numpy 기초] (0) | 2025.02.06 |
| 15일차 [ 데이터 시각화 심화 ] (0) | 2025.02.05 |
| 15일차 [ matplotlib ] (0) | 2025.02.04 |
| 14일차 [ 데이터 시각화 ] (0) | 2025.02.03 |