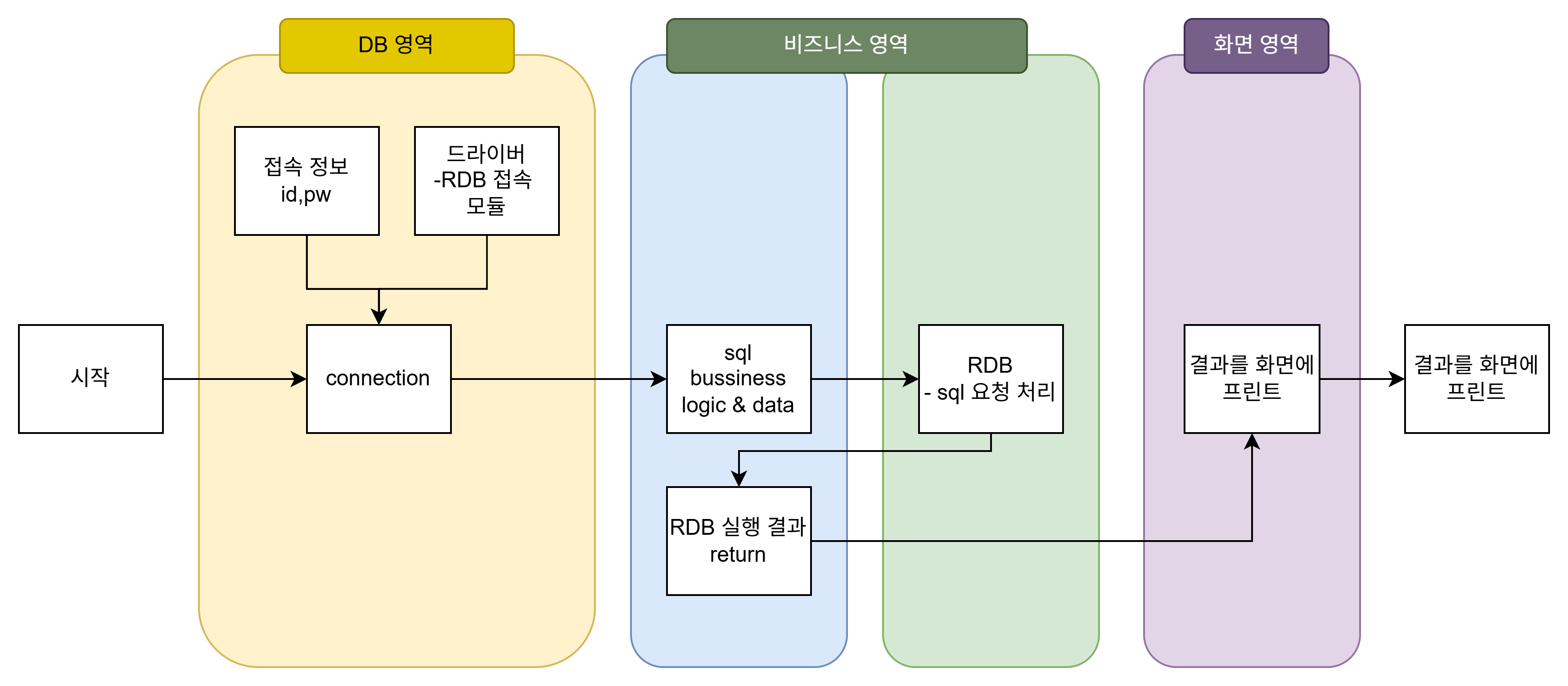
Langsmithhttps://colab.research.google.com/drive/1TIU5ysXZwsMaSV0_V5_cod_SJ7PQmsGW#scrollTo=suH4a5trQ0Go Google Colab NotebookRun, share, and edit Python notebookscolab.research.google.comTooltype hint https://colab.research.google.com/drive/1himSY0W0vmGvNvVxdGpzaUhDNL6htm9o#scrollTo=RdiSXp7XDNCh Google Colab NotebookRun, share, and edit Python notebookscolab.research.google.comlangsmith가 있어야 디버..