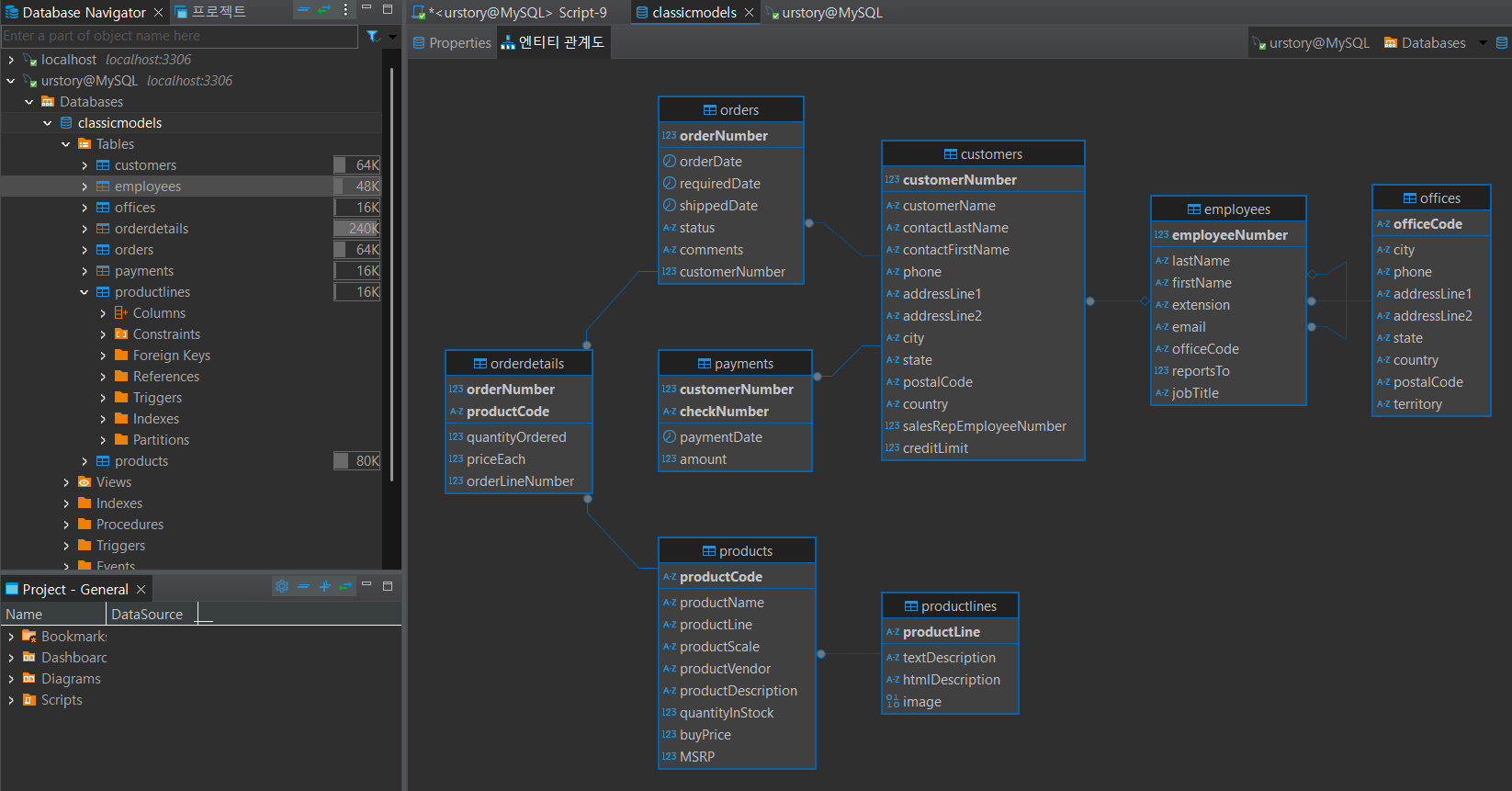
예제 디비 엔티티 관계도
Left Join
실무에선 left join, inner join 많이 쓴다.
left join에서 내가 조회하고 싶은 데이터의 테이블을 왼쪽에다 둔다.
/*
* 사용자 중에서 주문 많이 하는 사람?
* 필요 테이블: customers & orders
*
*/
/* A(table) Left join B(table)
* A table: 데이터 조회
* B table: 조건
*/
use classicmodels;
select
a.orderNumber
, a.status # 주문 상태
, a.orderDate
, b.customerName
from orders a # alias; table명 한칸 띄고 영문명 쓰면 별칭
left join customers b
on a.customerNumber = b.customerNumber
order by a.orderDate desc # 주문날짜 기준으로 조회
;
/* 주문 하지 않은 사람: 차집합
* a: customers / b: orders
* */
use classicmodels;
SELECT
count(a.customerNumber)
from customers a
left join orders b
on a.customerNumber = b.customerNumber
where 1=1
and b.customerNumber is null
;
# 122명 고객 중 24명이 아직 주문하지 않았다.
SELECT
count(a.customerNumber)
from customers a;
# 상태에 뭐가 있는지 group by로 안다.
# 테이블 조회시, 통계 데이터 (평균,unique) 추출하는 용도로 쓰임
select status from orders
group by status;
use classicmodels;
# 상품별 가격의 평균정보 조회
select avg(priceEach) # 상품별 가격의 평균
, count(orderNumber) # 상품별 주문 수
, productCode # 상품 정보
from orderdetails o
group by productCode
;
/* 사용자들 중 주문완료를 많이 하는 사람?
* 필요 테이블: customers & orders
*
* 실행 순서
* 0. select /from :데이터 선택/ 어디서 오는지
* 1. left join/ on :데이터 결합/어떤 조건
* 2. where : 필터링
* 3. group by >결과 그룹화: 통계정보 조회 : count(), avg()...
* 4. having >결과에 필터: 통계정보 조건문
* 5. order by > 최종 결과 정렬: 통계정보 정렬해서 보여줌 (항상 마지막)
*/
select
count(a.orderNumber) as cnt_order # 주문 개수
, b.customerName
from orders a # alias; table명 한칸 띄고 영문명 쓰면 별칭
left join customers b
on a.customerNumber = b.customerNumber
where 1=1
and a.status = 'Shipped'
group by a.customerNumber
having 1=1
and cnt_order > 5 # group by 결과에 대한 조건문
order by cnt_order desc
;
select
sum(quantityOrdered*priceEach) as money_of_product
from orderdetails
group by productCode
order by money_of_product desc;
# 고객들 중에 누가 가장 많이 돈을 썼는지? (주문완료 기준)
# orders, orderdtails join
select
o.customerNumber,
c.customerName
,sum(quantityOrdered*priceEach) as total_purchases
from orders o
left join orderdetails od
on o.orderNumber = od.orderNumber
left join customers c
on o.customerNumber = c.customerNumber
where 1=1
and o.status='Shipped'
group by o.customerNumber
order by total_purchases desc
;
# 년도별 어느 사무실이 가장 돈을 많이 벌었는지?
# 필요 테이블: offices
# 각 오피스별 고용직원들이 고객들에게 판 주문 디테일의 총합
# 여기 채워보기
select
o.orderDate
from orders o
left join employees e on
left join customers c
left join orderdetails odpython & MySQL
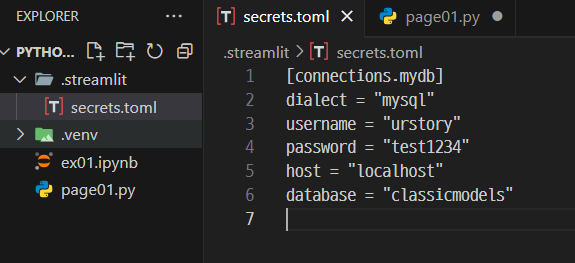
- MySQL connection 객체가 있어야 mysql서버와 소통이 된다.
- pip install PyMySQL
- connection 생성하기
import pymysql
connection = pymysql.connect(
host="localhost",
user="urstory",
password="test1234",
database="classicmodels",
charset="utf8"
)
cursor=connection.cursor(pymysql.cursors.DictCursor) # col name 알아보려고 함.
sql = "show tables"
cursor.execute(sql)
cursor.fetchall()
"""
[{'Tables_in_classicmodels': 'customers'},
{'Tables_in_classicmodels': 'employees'},
{'Tables_in_classicmodels': 'offices'},
{'Tables_in_classicmodels': 'orderdetails'},
{'Tables_in_classicmodels': 'orders'},
{'Tables_in_classicmodels': 'payments'},
{'Tables_in_classicmodels': 'productlines'},
{'Tables_in_classicmodels': 'products'}]
"""1) 설치 라이브러리
# terminal
8 pip install PyMySQL
9 clear
10 pip install streamlit
11 streamlit hello
12 pip install SQLAlchemy
13 pip install mysqlclient2) streamlit 에 sql 결과를 dataframe으로 해서 보이기
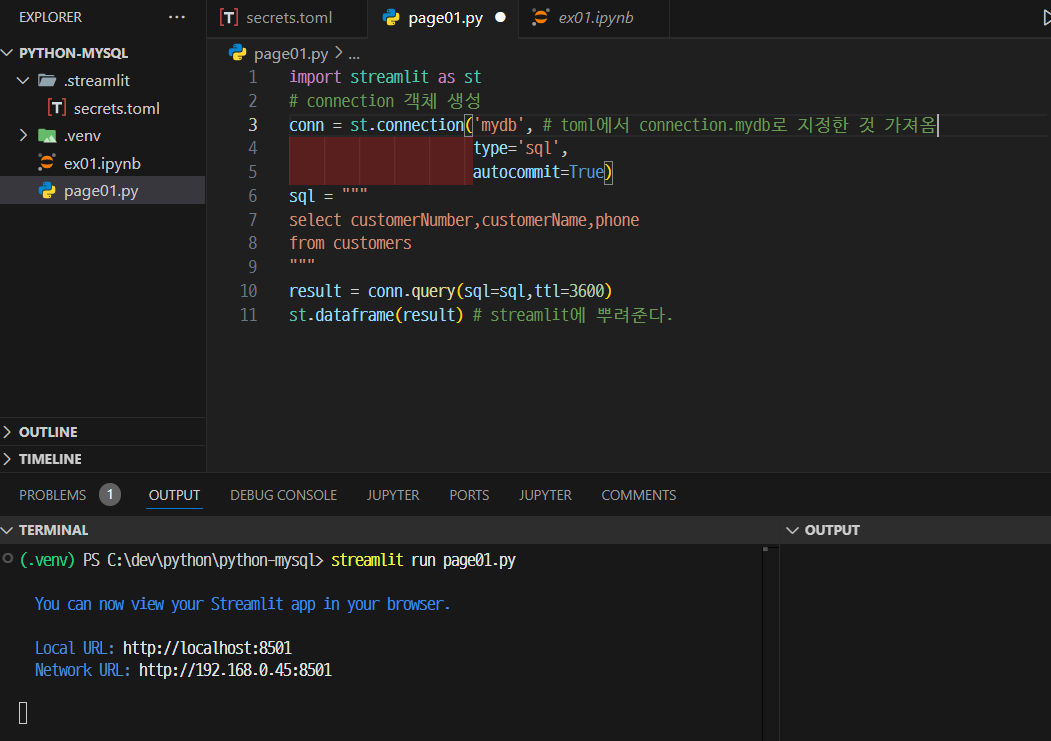
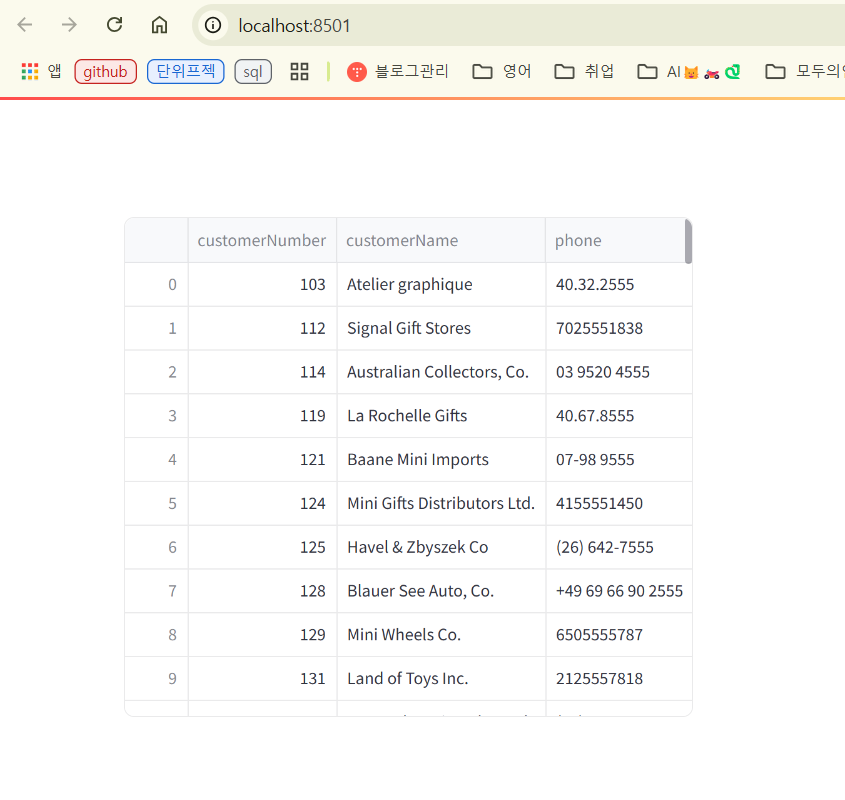
Streamlit Docs
Join the community Streamlit is more than just a way to make data apps, it's also a community of creators that share their apps and ideas and help each other make their work better. Please come join us on the community forum. We love to hear your questions
docs.streamlit.io
자세한 건 streamlit docs 참고!
streamlit 실습
실습1. 기본
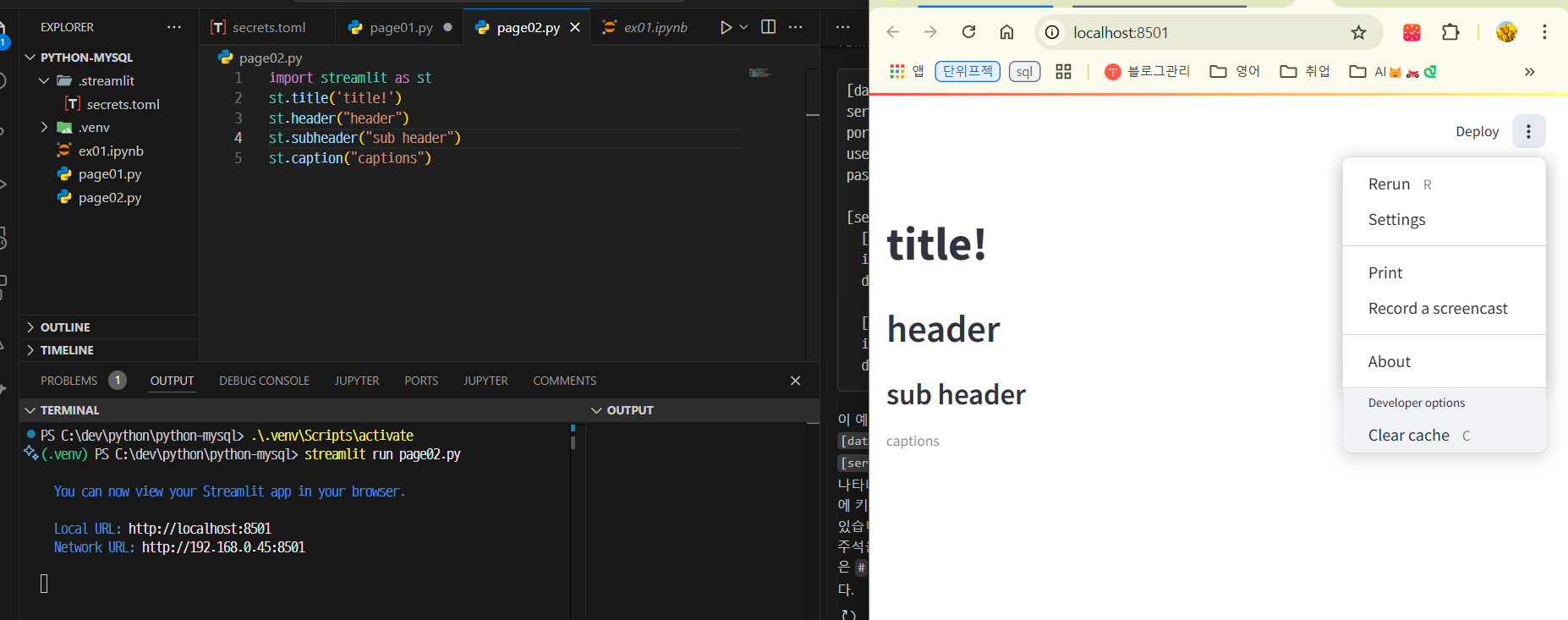
import streamlit as st
st.title('title! :wave:')
st.header("header")
st.subheader("sub header")
st.caption("captions")
sample_python_code ="""
def add(a,b):
return a+b
"""
st.code(sample_python_code,"python")
st.text('일반 텍스트 작성 :wave:')
st.markdown("streamlit은 **markdown**문법을 지원하고 있어요.")
st.markdown("""
## 오늘의음식
- 삼겹살
- 치맥
- 떡볶이
""")
st.latex(r'\sqrt{x^2+y^2}=1')
이모지
streamlit app
App showing all the emoji shortcodes supported by Streamlit
streamlit-emoji-shortcodes-streamlit-app-gwckff.streamlit.app
수식어
Streamlit Docs
Join the community Streamlit is more than just a way to make data apps, it's also a community of creators that share their apps and ideas and help each other make their work better. Please come join us on the community forum. We love to hear your questions
docs.streamlit.io
텍스트 레퍼런스
Streamlit Docs
Join the community Streamlit is more than just a way to make data apps, it's also a community of creators that share their apps and ideas and help each other make their work better. Please come join us on the community forum. We love to hear your questions
docs.streamlit.io
실습2. dataframe
import pandas as pd
import streamlit as st
import numpy as np
df_random = pd.DataFrame(
np.random.randn(50,20),
columns=("col %d"%i for i in range(20))
)
st.title("DataFrame")
st.dataframe(df_random.style.highlight_max(axis=0))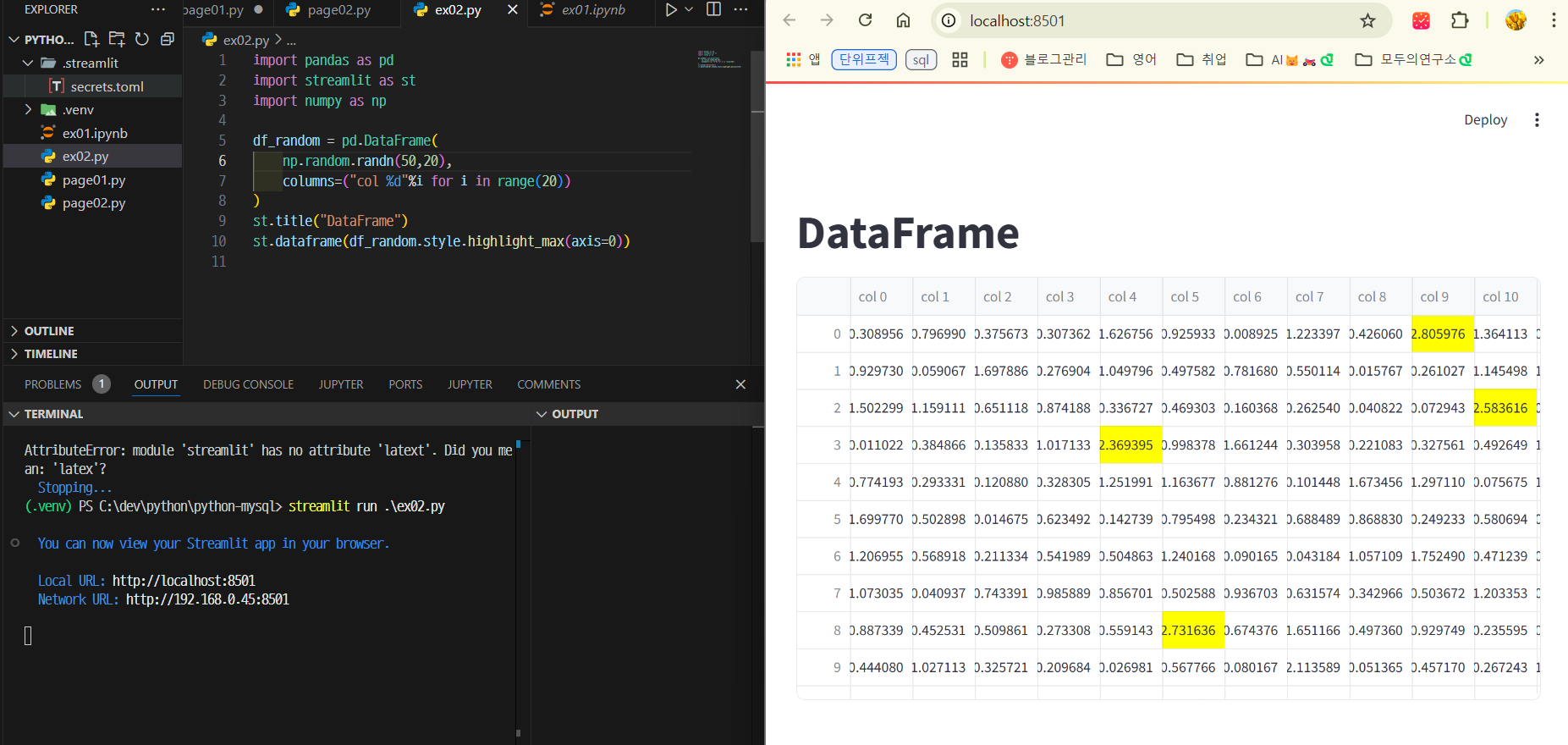
실습3. 표, 별표 표시
import random
import pandas as pd
import streamlit as st
df = pd.DataFrame(
{
"name": ["Roadmap", "Extras", "Issues"],
"url": ["https://roadmap.streamlit.app", "https://extras.streamlit.app",
"https://issues.streamlit.app"],
"stars": [random.randint(0, 1000) for _ in range(3)],
"views_history": [[random.randint(0, 5000) for _ in range(30)]
for _ in range(3)],
}
)
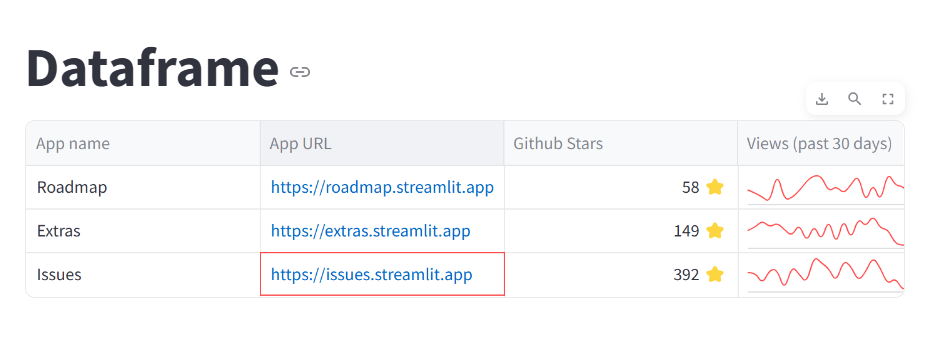
st.title('Dataframe')
st.dataframe(
df,
column_config={
"name": "App name",
"stars": st.column_config.NumberColumn(
"Github Stars",
help="Number of stars on GitHub",
format="%d ⭐",
),
"url": st.column_config.LinkColumn("App URL"),
"views_history": st.column_config.LineChartColumn(
"Views (past 30 days)", y_min=0, y_max=5000
),
},
hide_index=True,
)
실습4. use_container_width
import pandas as pd
import streamlit as st
# Cache the dataframe so it's only loaded once
@st.cache_data
def load_data():
return pd.DataFrame(
{
"first column": [1, 2, 3, 4],
"second column": [10, 20, 30, 40],
}
)
df = load_data()
st.title('Dataframe')
# Boolean to resize the dataframe, stored as a session state variable
st.checkbox("Use container width", value=False, key="use_container_width")
# Display the dataframe and allow the user to stretch the dataframe
# across the full width of the container, based on the checkbox value
st.dataframe(df, use_container_width=st.session_state.use_container_width)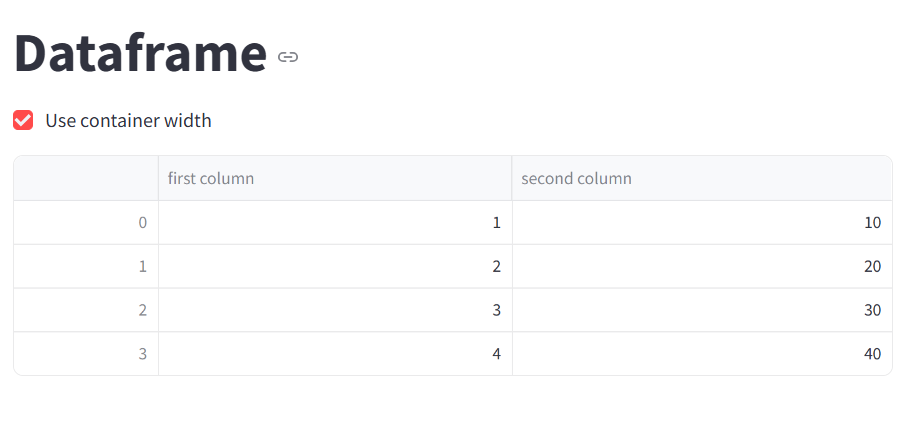
https://docs.streamlit.io/develop/api-reference/data
Streamlit Docs
Join the community Streamlit is more than just a way to make data apps, it's also a community of creators that share their apps and ideas and help each other make their work better. Please come join us on the community forum. We love to hear your questions
docs.streamlit.io
Streamlit Docs
Join the community Streamlit is more than just a way to make data apps, it's also a community of creators that share their apps and ideas and help each other make their work better. Please come join us on the community forum. We love to hear your questions
docs.streamlit.io
'SK Networks Family AI bootcamp 강의노트' 카테고리의 다른 글
| 11일차 [ Web crawling ] (1) | 2025.01.21 |
|---|---|
| 11일차 [ streamlit ] (0) | 2025.01.21 |
| 10일차 [ github (clone, branch,merge) ] (0) | 2025.01.20 |
| [플레이데이터 SK네트웍스 Family AI캠프 10기] 2주차 회고 (0) | 2025.01.17 |
| 9일차 [SQL(DML)] (0) | 2025.01.17 |