refer: 현재 표시하는 웹페이지가 어떤 웹페이지에서 요청하는지에 대한 정보. 일반 사용자인지, 해커 혹은 개발자인 지 알 수있다.
크롤링 & streamlit
# common/crawling.pyimport requests
defdo_crawling():
url = "https://n.news.naver.com/mnews/hotissue/article/011/0004440387?type=series&cid=2002544"# header가 없으면 높은 확률로 접속이 거부됨.
header = {
# 어떤 사람이 어떤 디바이스 (pc or mobile, etc)에서 접속했는지 접속 정보 가짐."User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36\
(KHTML, like Gecko) Chrome/132.0.0.0 Safari/537.36",
# 현재 표시하는 웹페이지가 어떤 웹페이지에서 요청되었는지 "Referer" : "https://news.naver.com/aside?oid=011"
}
response = requests.get(url=url, headers=header)
return"오류가 발생했어요"if response.status_code >= 400else'성공했어요.'# main.pyimport streamlit as st
from common.crawling import do_crawling
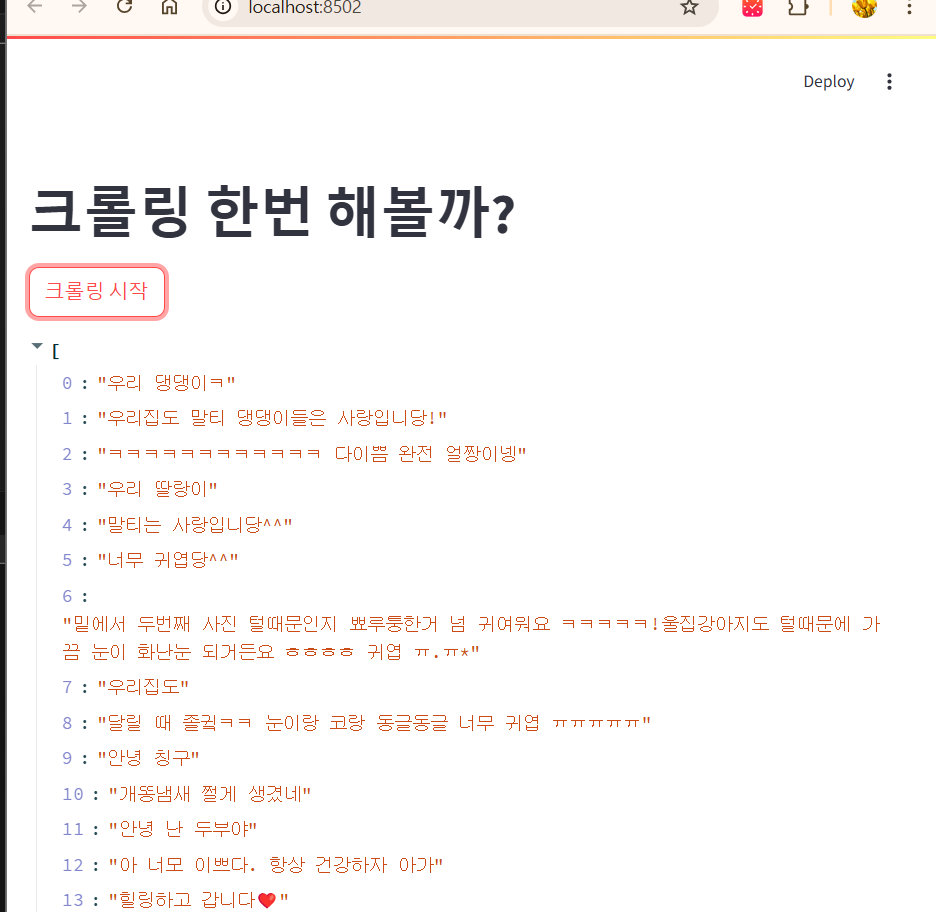
st.title('크롤링 한번 해볼까?')
if st.button("크롤링 시작"):
res=do_crawling()
st.write(res)
네이트 판 글의 댓글 긁어오기
import requests
from bs4 import BeautifulSoup as bs
url = "https://pann.nate.com/talk/350939697"
header = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) \
AppleWebKit/537.36 (KHTML, like Gecko) \
Chrome/132.0.0.0 Safari/537.36",
"Referer":"https://shop.nate.com/"
}
response = requests.get(url=url,headers=header)
print(response)
if response.status_code>=400:
print('error!!')
print(response.text)
beautiful_text = bs(response.text,"html.parser")
beautiful_text
response.text #로 그냥 가져오면 일자로 가져온다.#==> 너무 길어서 읽기도 힘들고 데이터 긁어오기도 힘들다. 그래서 필요한게 beautifulsoup"""
<Response [200]>
<!DOCTYPE HTML>
<html lang="ko">
<head>
<meta charset="utf-8" />
<meta name="viewport" content="width=device-width, initial-scale=1" />
<meta http-equiv="X-UA-Compatible" content="IE=edge" />
<title>우리집 댕댕이 | 네이트 판</title>
<link href="/favicon.ico?m=3.3.26" type="image/x-icon" rel="shortcut icon" />
<link href="/pann_css/content_css.css?m=3.3.26" rel="stylesheet" type="text/css" media="all" charset="utf-8" /><link href="/css/common_pann_v4.css?m=3.3.26" rel="stylesheet" type="text/css" media="all" charset="utf-8" /><link href="/css/aticle_v3.css?m=3.3.26" rel="stylesheet" type="text/css" media="all" charset="utf-8" /><link href="/css/editor.css?m=3.3.26" rel="stylesheet" type="text/css" media="all" charset="utf-8" />
<link href="/images/nate_pann.png?m=3.3.26" rel="apple-touch-icon-precomposed" /><link href="/images/nate_pann.png?m=3.3.26" rel="apple-touch-icon" />
<script src="/js/common.js?m=2.2.8" type="text/javascript" ></script>
<script src="/js/jquery-1.9.1.js?m=2.2.8" type="text/javascript" ></script>
<script type="text/javascript" >
var j$ = jQuery.noConflict();
</script>
<!-- <script type="text/javascript" src="/js/prototype.js"></script> -->
<script src="/js/editor.js?m=2.2.8" type="text/javascript" ></script>
<script src="/flash/skiui.js?m=2.2.8" type="text/javascript" ></script>
<script src="//common.nate.com/textGNB/commonTextGNBV1?m=pann" type="text/javascript" charset="utf-8"></script>
<script type="text/javascript" charset="utf-8">
// <