웹크롤링 - 글 아이디 넣어서 스트림릿에서 크롤링 해보기
vscode: F2는 함수명 한번에 변경
# crawling.py
import requests
from bs4 import BeautifulSoup as bs
def do_crawling_of_nate(comment_id:str):
# url = "https://pann.nate.com/talk/350939697"
url = f"https://pann.nate.com/talk/{comment_id}"
header = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) \
AppleWebKit/537.36 (KHTML, like Gecko) \
Chrome/132.0.0.0 Safari/537.36",
"Referer":"https://shop.nate.com/"
}
response = requests.get(url=url, headers=header)
return response
def get_comments(comment_id:str):
response = do_crawling_of_nate(comment_id)
if response.status_code>=400:
print('error!!')
return
beautiful_text = bs(response.text,"html.parser")
dd_list = beautiful_text.find_all("dd",class_="usertxt")
result = [dd.get_text().replace("\n","").strip()
for dd in dd_list ]
# dd_list[0].get_text().replace("\n","").strip()
return result
# main.py
import streamlit as st
from common.crawling import do_crawling_of_nate
from common.crawling import get_comments
st.title('크롤링 한번 해볼까?')
with st.form("my form"):
nate_pann_id = st.text_input("네이트 판 아이디 작성해주세요.")
form_submit = st.form_submit_button("크롤링 시작합니다.")
if form_submit and nate_pann_id is not None:
# if st.button("크롤링 시작"):
msg=get_comments(nate_pann_id)
st.write(msg)
# terminal
streamlit run main.py
DB연동
아이디 생성, 디비 생성, 권한 주기
/*
* generate nate pann id
* */
create user 'nate_pann'@'%'
identified by 'n1234';
use mysql;
show tables;
select * from user;
/*
* generate DB
* */
create database nate_db;
show databases;
/*
* 계정 권한 부여
*/
grant all privileges
on nate_db.*
to 'nate_pann'@'%';네이트판 댓글에서 내용 더 가져오기
DB 생성
# root 계정에서 진행
use nate_db;
create table if not exists nate_pann_comments(
-- comment_id int unsigned auto_increment comment '댓글 아이디',
pann_id varchar(20) not null comment '네이트판 아이디',
title varchar(20) not null comment '댓글 제목',
comment varchar(200) not null comment '댓글 내용',
create_dt timestamp comment '생성일자',
primary key(pann_id, create_dt)
)engine=innodb default charset=utf8 comment='네이트판 댓글';DB에 들어갈 크롤링한 데이터 포맷팅
import requests
from bs4 import BeautifulSoup as bs
from datetime import datetime
def do_crawling_of_nate(comment_id:str):
# url = "https://pann.nate.com/talk/350939697"
url = f"https://pann.nate.com/talk/{comment_id}"
header = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) \
AppleWebKit/537.36 (KHTML, like Gecko) \
Chrome/132.0.0.0 Safari/537.36",
"Referer":"https://shop.nate.com/"
}
response = requests.get(url=url, headers=header)
return response
def get_comments(comment_id:str):
response = do_crawling_of_nate(comment_id)
if response.status_code>=400:
print('error!!')
return
beautiful_text = bs(response.text,"html.parser")
comments_list = beautiful_text.find_all("dl",class_="cmt_item")
return [{
'title':comments_list[0].find(class_='nameui'),
'comment':comments_list[0].find(class_='nameui').get_text(),
'create_dt':datetime.strptime(comments_list[0].find('i').get_text(),'%Y.%m.%d %H:%M')
} for comment in comments_list]
DB와 연결
- `pip install mysqlclient' : python 과 MySQL 연결
- 'pip install SQLAlchemy'
- ORM (Object Relational Mapping), python(object)와 DB 간의 통역가,
- 객체 지향적으로 데이터베이스 작업
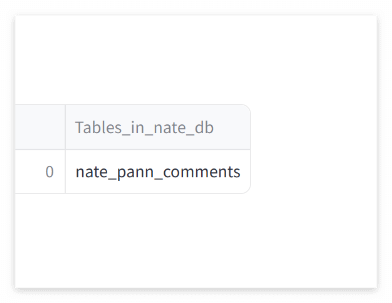
streamlit과 DB 연결된 스크립트 연동 (테스트용으로 show tables)
# .streamlit/secrets.toml
[connections.mydb]
dialect = "mysql"
username = "nate_pann"
password = "n1234"
host = "127.0.0.1"
database = "nate_db"
# pages/test_db.py
import streamlit as st
conn = st.connection("mydb",type='sql',autocommit=True)
df = conn.query("show tables",ttl=3600)
st.dataframe(df)
크롤링한 댓글을 스트림릿으로 보여주기
# common/crawling.py
import requests
from bs4 import BeautifulSoup as bs
from datetime import datetime
def do_crawling_of_nate(comment_id:str):
# url = "https://pann.nate.com/talk/350939697"
url = f"https://pann.nate.com/talk/{comment_id}"
header = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) \
AppleWebKit/537.36 (KHTML, like Gecko) \
Chrome/132.0.0.0 Safari/537.36",
"Referer":"https://shop.nate.com/"
}
response = requests.get(url=url, headers=header)
return response
def get_comments(comment_id:str):
response = do_crawling_of_nate(comment_id)
if response.status_code>=400:
print('error!!')
return
beautiful_text = bs(response.text,"html.parser")
comments_list = beautiful_text.find_all("dl",class_="cmt_item")
return [
{# 댓글의 id
'pann_id':comment_id,
# 댓글의 타이틀
'title':comment.find(class_="nameui").get_text().strip(),
# 댓글
'comment':comment.find("dd", class_="usertxt").get_text().replace("\n", "").strip(),
# 댓글 생성일짜
'create_dt':datetime.strptime(comment.find("i").get_text().strip(), '%Y.%m.%d %H:%M')
} for comment in comments_list
]
# common/databse.py
import streamlit as st
from .sql_constant import INSERT_SQLs
from sqlalchemy import text
# cache: 하나의 객체(데이터)를 재사용하기 위해서 cache 메모리에 저장
@st.cache_resource
def get_connector():
return st.connection(
"mydb",type="sql",
autocommit=True
)
def insert_query(sql_constant:INSERT_SQLs,data:list) -> list:
conn = get_connector()
list_error=[]
for datum in data:
try:
insert_sql = sql_constant.value[1].format(
pann_id = datum['pann_id'],
title = datum["title"],
comment = datum["comment"],
create_dt = datum["create_dt"]
)
conn.connect().execute(text(insert_sql))
except Exception as e:
list_error.append((datum,e))
return list_error
# common/sql_constant.py
import enum
class INSERT_SQLs(enum.Enum):
NATE_PANN_COMMENTS = (enum.auto(), """
insert nate_pann_comments
(pann_id, title,comment,create_dt)
values('{pann_id}','{title}','{comment}','{create_dt}');
""","댓글 데이터 저장")
# main.py
import streamlit as st
from common.crawling import do_crawling_of_nate
from common.crawling import get_comments
from common.database import insert_query
from common.sql_constant import INSERT_SQLs
st.title('크롤링 한번 해볼까?')
with st.form("my form"):
nate_pann_id = st.text_input("네이트 판 아이디 작성해주세요.")
form_submit = st.form_submit_button("크롤링 시작합니다.")
if form_submit and nate_pann_id is not None:
# if st.button("크롤링 시작"):
comments = get_comments(nate_pann_id)
list_error = insert_query(INSERT_SQLs.NATE_PANN_COMMENTS,comments)
if not list_error:
st.write('저장 성공')
else:
st.write(list_error)오늘 배운건 크롤링한 내용을 디비에 저장해서 스트림릿에까지 보여주는 것!!
디비에 저장한 내용을 보여주는 것이 중요한 것 같은데... 깃헙에서 공유해준 것까지 분석해서 플젝에 적용해봐야겠다.
class_web/6. crawling at main · good593/class_web
Contribute to good593/class_web development by creating an account on GitHub.
github.com
'SK Networks Family AI bootcamp 강의노트' 카테고리의 다른 글
| 13일차 [ 데이터분석: Pandas ] (0) | 2025.01.31 |
|---|---|
| [플레이데이터 SK네트웍스 Family AI캠프 10기] 3주차 회고 (1) | 2025.01.24 |
| 토이 프로젝트 일정 (자동 코인 매매 봇) (0) | 2025.01.21 |
| 11일차 [ Web crawling ] (1) | 2025.01.21 |
| 11일차 [ streamlit ] (0) | 2025.01.21 |